Scaling Redis in Containerized Environments

Redis, standing for Remote Dictionary Server, is a household name in the world of high-performance key-value stores. Its speed and simplicity have made it the go-to solution for caching, session storage, and real-time analytics. In our latest project at Instituto Superior Técnico, University of Lisbon, my colleagues Diogo Jesus, and Leonardo Cruz and I have taken a deep dive into the deployment and scalability of Redis within containerized environments. Our aim is to unpick the fabric of Redis’s performance and scalability, analyzing its behavior in a distributed context.
Containerization and Redis Deployment
The journey begins with the deployment of a Redis master-replica cluster using Helm charts, particularly the one offered by Bitnami. This tool provided us with extensive configurability, crucial for tailoring the deployment to our specific requirements. Our attention to detail extended to the allocation of CPU and memory resources, ensuring that the deployed system was neither resource-starved nor excessively provisioned.
Balancing Resources
For our baseline configuration, we set CPU limits to 100 millicpu units and memory limits to 500Mi. These settings aimed to balance performance and resource efficiency, providing enough leeway for Redis to handle a variety of operations concurrently without falling prey to memory pressure or CPU starvation. Redis Persistence
To ensure data durability, we enabled Redis’s persistence feature. The use of Append-Only Files (AOF) logs guarantees that operations can be replayed to restore a server, adding a layer of resilience to our setup. Benchmarking Redis Performance
To understand Redis’s performance, we put it to the test using redis-benchmark. We simulated a real-world scenario with 100 parallel connections and a total of 1 million requests, focusing on set and get operations to evaluate both write and read capabilities.
The Scalability Saga
Redis’s scalability manifests through various mechanisms:
- Master-Slave Replication: Distributes read requests to handle increasing load while keeping latencies low.
- Partitioning: Accommodates larger data sets and higher throughput by distributing data across instances.
- Persistence: Balances performance and data durability, with strategies like RDB snapshots and AOF log files.
- Redis Cluster: Utilizes multicore architectures for sharding data across nodes and maintaining availability during node failures.
Latency vs. Throughput
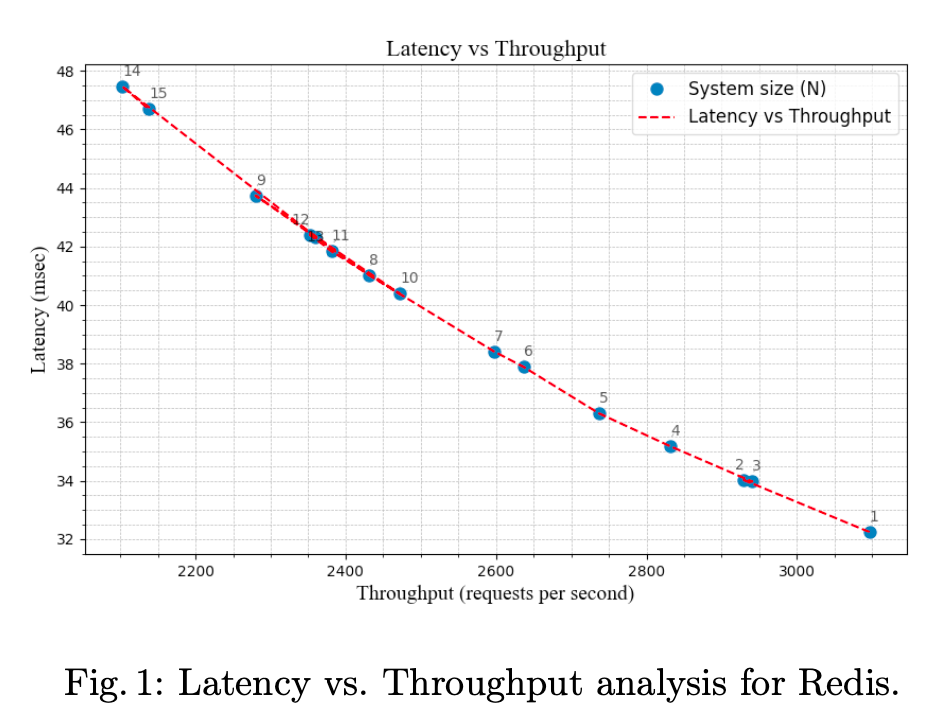
Our analysis highlighted the trade-off between data durability and performance. As the number of replica nodes increased, so did the latency due to the overhead of synchronization across nodes. Interestingly, certain replica counts revealed latency peaks, hinting at potential bottlenecks.
Applying the Universal Scalability Law (USL)
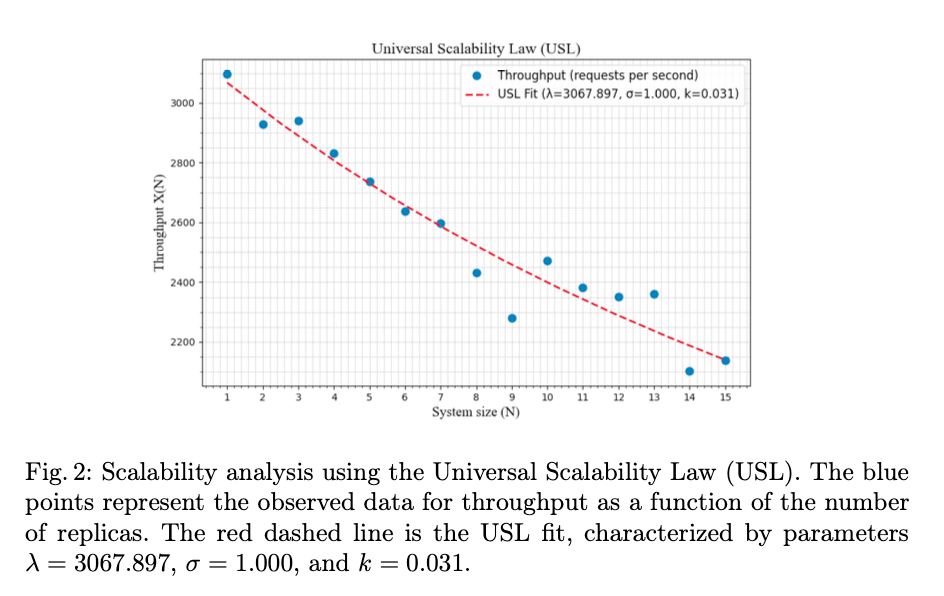
Using the USL, we quantified scalability and found that throughput does not increase linearly with the number of replicas. The analysis indicated the impact of memory contention in multi-node setups and delays induced by replication and clustering mechanisms.
Dissecting Redis Requests
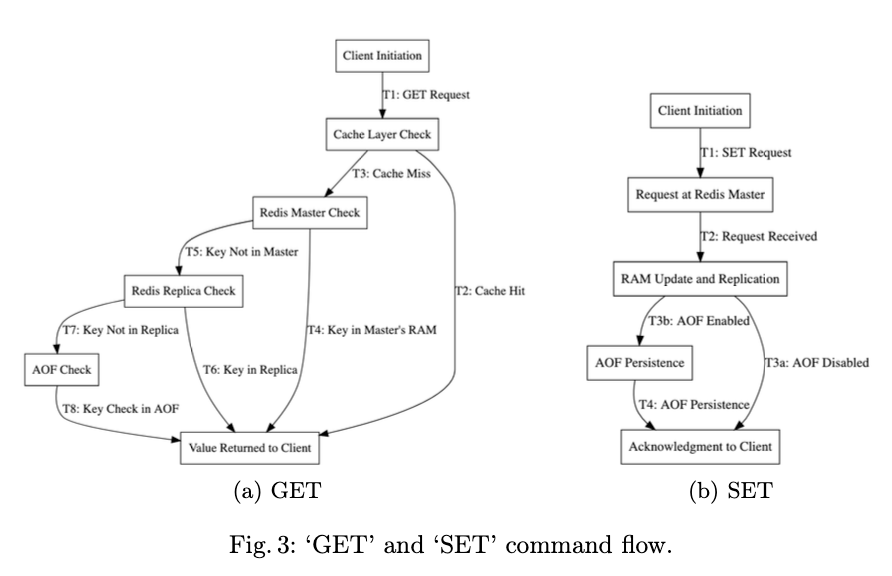
A closer examination of the GET and SET command flows revealed the nuances of operations within Redis. A cache hit on a GET operation leads to a fast retrieval path, while enabling persistence impacts the SET operation flow, albeit less significantly.
Final Thoughts
Our project delves into the complexities of scaling Redis in a containerized environment. Through careful configuration, rigorous benchmarking, and analytical rigor using the USL, we have shed light on the delicate balance between resource efficiency and performance in distributed systems. Our exploration not only highlighted the scalability characteristics of Redis but also provided insights into its operational behavior, ensuring that our findings contribute to the broader understanding of managing large-scale distributed systems effectively.
The detailed study, spearheaded by André Ribeiro, Diogo Jesus, and Leonardo Cruz, is a testament to the capabilities of Redis as a scalable, high-performance key-value store. We hope that the insights gleaned from this research aid others in deploying and scaling Redis within their own containerized ecosystems.
For further details and to see our findings, please refer to our project’s Git repository and the associated figures illustrating our scalability analysis and command flow decomposition.
For tech enthusiasts and professionals alike, the scalability and performance analysis of Redis presented in this blog post can offer valuable knowledge in engineering large-scale systems. Redis proves to be as robust and reliable as it is performant, a beacon for developers and system architects aiming for efficiency at scale.
Would you like to delve deeper into our findings? Do not hesitate to reach out or explore our GitHub repository for the full array of insights and data points gathered throughout this phase of our project.
(Note: This post has been adapted from a technical project abstract to suit a blog format. Some content has been simplified for the target audience.)