Hackathon across the Globe

For my first ever Hackathon I had two real challenges. The lack of sleep, and creating an AI-Enabled Assessment Marking with the use of ML-based text mining algorithm.
Big Data Society of Macquarie University
Organised by Macquire University Big Data Society and sponsored by Microsoft, AIP Research Center, and ITIC, this Hackthon was for the first time remote whilst being hosted in Australia.
The prizes rounded over 6000$ where my team got the distinguished spot number one and was granted the first prize.
Granted, we did lose some sleep, as Australia’s time zone is 11 hours difference from Lisbon’s1
The Hackathon Competition
The Hackathon had three different challenges, where the first was the most challenging and the last two were entry-level. We decided to focus on the first.
The Problem was the following:
- Help professors mark an essay in an automated way
- Create a marking application front-end layer to input the data and be presented with some results
This was the Architecture that we decided to use: 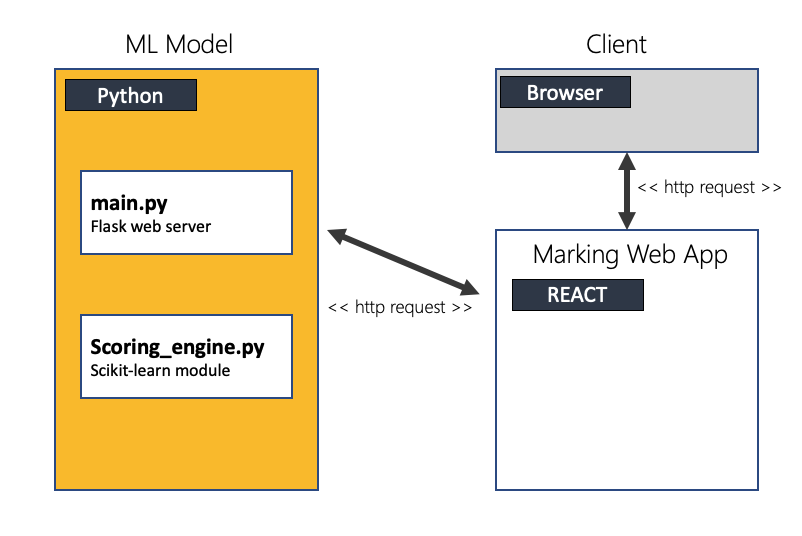
The main focus really relies on the scoring_engine.py where the rest of the page will mention it in more detail, but first…
Data Preparation
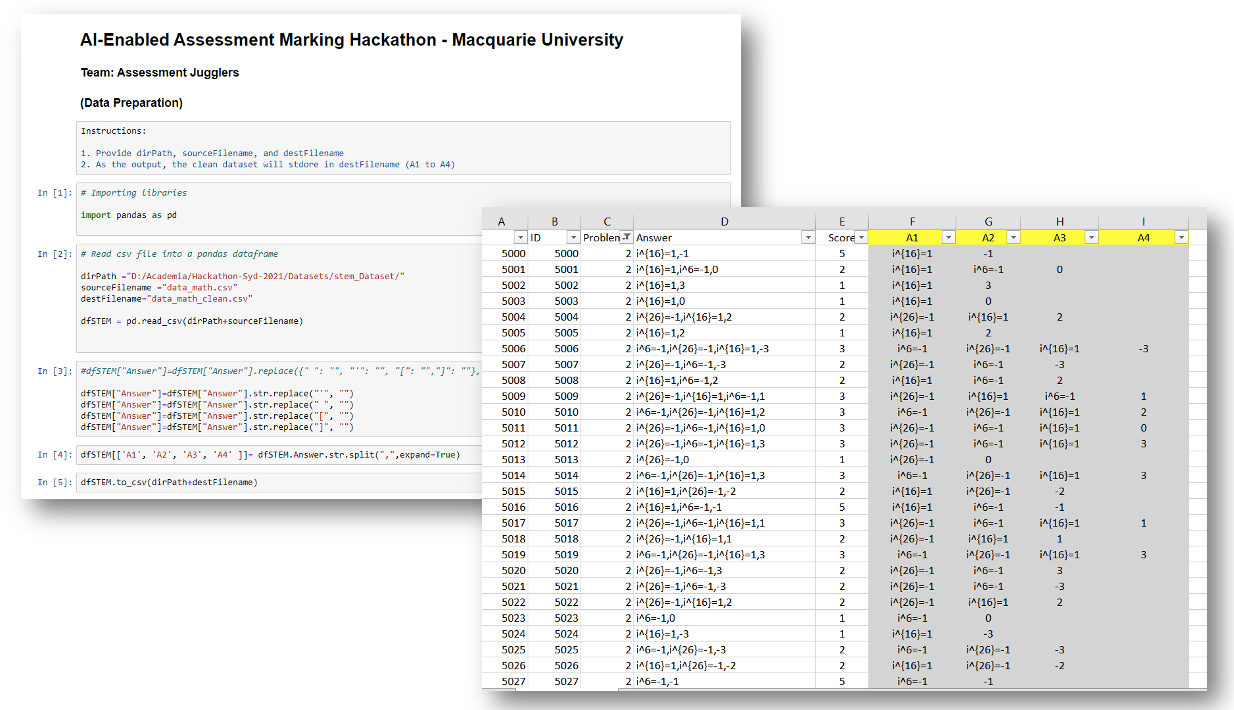 As part of the challenge, the given dataset wasn’t totally prepared to be used in a machine learning algorithm. Some tokens weren’t correct and so we used Regex operations to parse them into their more consistent state.
As part of the challenge, the given dataset wasn’t totally prepared to be used in a machine learning algorithm. Some tokens weren’t correct and so we used Regex operations to parse them into their more consistent state.
Most of this work was done in Excel and for some small tweaks on the answer fields (our independent variable) we used a simple script in Python
Machine Learning Model
We chose a Naive Bayes Algorithm with a bag of words to train our model.
We split the dataset into training, test and validation as follows:
| Training | Test | Validation |
|---|---|---|
| 70% | 25% | 5% |
To create our model we used Scikit-Learn which the group was very used to and could immediately start working. There were two important functions that we needed to create, the training function and the prediction function in order to fit the model into our cleaned dataset and get some output from previously unseen inputs.
Training Function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def _train_model(df):
print('Training model...')
DV = "Score" # the dependent variable, text is the independent variable here
X = df.drop([DV], axis=1) # drop from our X array because this is the text data that gets trained
y = df[DV]
# we train on 70% of the data, test on the rest
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
# Build bag of words
count_vect = CountVectorizer(token_pattern="[^\s]*", max_features=100)
X_train_counts = count_vect.fit_transform(X_train["Answer"])
print(count_vect.vocabulary_) # Print vocabulary
X_test = count_vect.transform(X_test["Answer"])
# fit the training dataset on the NB classifier
Naive = MultinomialNB()
Naive.fit(X_train_counts, y_train)
# predict the labels on validation dataset
predictions_NB = Naive.predict(X_test)
# Use accuracy_score function to get the accuracy
return {"naive": Naive, "vocabulary": count_vect, "accuracy": accuracy_score(predictions_NB, y_test) * 100}
Prediction Function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def _predict(model, df):
Naive = model["naive"]
count_vect = model["vocabulary"]
answers = []
# Calculate marking for each row
for index, row in df.iterrows():
answer = [row['Answer']]
answer_vect = count_vect.transform(answer) # create bag of words
predict_onion = Naive.predict(answer_vect) # applying it to the trained model
value_as_int_array = predict_onion.astype(int)
# Score the answers
grade = value_as_int_array[0]
answers.append({"id": int(row["ID"]), "answer": row["OriginalAnswer"], "grade": int(grade)})
return answers
We also created a function to validate the model which gave us some impressive results.
It is important to note that the challenge was divided into four individual problems, each with more complex phrases than the last, these were the results
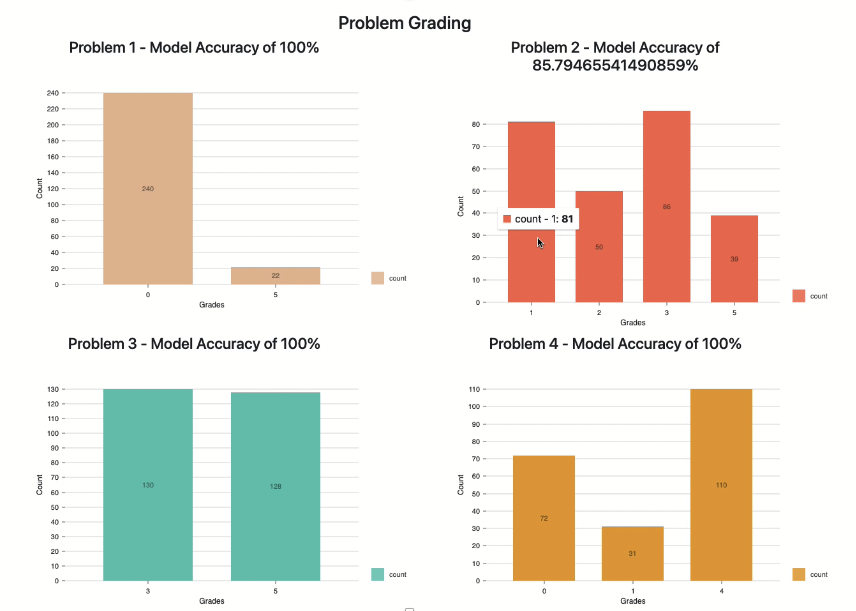
| Problem # | Size of Dataset | Accuracy |
|---|---|---|
| 1 | 262 | 100% |
| 2 | 256 | 86% |
| 3 | 258 | 100% |
| 4 | 213 | 100% |
The image presented is auto-generated from our front-end layer that we created using React and Nivo.
Finishing Touches
We created a back-end server with Flask in order to server the machine learning model. We selected this framework as it’s simple for our use-case and is also written in Python.
The team was also created a simple website where we could upload the answers of the students (in this case, the dataset) using React and Nivo.
Conclusion
Given the end of the Hackathon, our team pitched the project and two hours later whilst I was sleeping we were announced as the winning team for Problem number one!
And so it was, we won a Hackathon competition, all the way across the globe :D
Thank you to my team! 